
在现代科学研究中,数据分析成为一个不可或缺的环节。尤其是在农业领域,通过对肉质高品质数据的深入分析,可以帮助我们更好地理解动物养殖过程中的关键因素,从而提升产品质量和生产效率。R语言作为一种强大的统计计算工具,在这一领域发挥着重要作用。本文将围绕“好看的肉质高”的主题,探讨如何利用R进行有效的数据挖掘与分析。
数据收集与整理
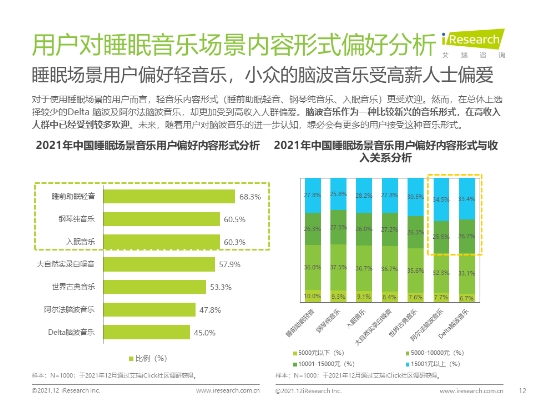
首先,我们需要从各种来源(如实验室检测、生产记录等)收集相关数据,然后使用R语言进行清洗和整理。这一过程对于确保后续分析结果的准确性至关重要。在这一步骤中,我们可以使用R中的read.csv()函数来读取CSV文件,以及merge()函数来合并不同来源的数据。
特征选择与处理

接下来,我们需要根据实际问题挑选出那些能够影响肉质高品质的特征,并对这些特征进行适当处理。这可能包括标准化、归一化等技术,以便于后续模型训练。在这个阶段,R提供了丰富的手段,如scale()函数用于标准化变量,以及normalize()函数用于归一化变量。
建立模型与预测
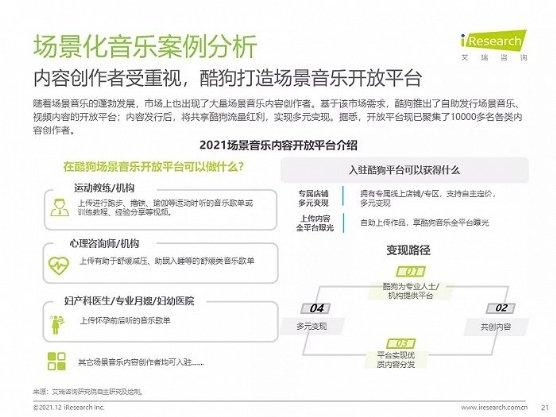
建立数学模型是提高预测准确性的关键一步。利用这些经过处理好的特征,我们可以构建不同的统计模型,如回归模型、决策树、随机森林等。在这方面,R语言提供了广泛的一系列包,如"stats"包内置了常用的线性回归方法,而"randomForest"包则专门为构建随机森林提供支持。
模型评估与优化

为了验证我们的模型是否有效以及它能否在新环境下得到应用,我们需要通过交叉验证等方法对其进行评估。如果发现存在不足之处,可以进一步调整参数或者尝试其他算法以达到最佳效果。在这方面,R还提供了一些工具,如"AUC()"函数用来计算ROC曲线下的面积,以评价分类器性能。
结果解释与可视化
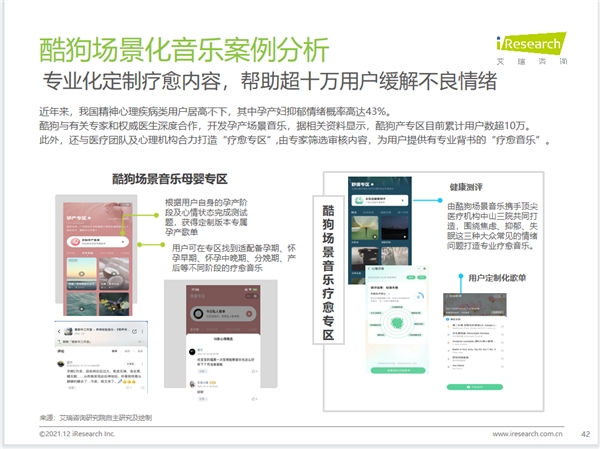
最后,将所有结果转换成易于理解和沟通形式是非常重要的一步。这通常涉及到将复杂数值转换为图形表示,使得非专业人士也能轻松理解。例如,可以使用"Ggplot2"包创建直方图、箱形图或者散点图,以直观展示各个因素之间关系及其影响程度。
结论 & 推荐实践
总结本次探索之旅,我们了解到了利用R实现良好的肉类质量控制有多么简单且强大。此外,由于不断进步,这个领域还会出现更多新的技术和算法,因此建议我们持续关注最新动态,并根据实际需求定期更新我们的技能库,为未来的工作做好准备。